Service Discovery
- Service Discovery란?
- 컴퓨터 네트워크에서 장치 및 서비스를 자동으로 검색 서비스 검색
- 프로토콜 (SDP)은 서비스 검색을 수행하는 데 도움이되는 네트워크 프로토콜
- Service Discovery는 사용자의 구성 노력을 줄이는 것을 목표
- Service Discovery를 사용해야 하는 이유
- 클라우드 네이티브 서비스는 동적
- 서비스는 필요에 따라 생성, 소멸
- 서비스 생성, 소멸에 상관없이 연계 서비스는 동작 필요
- IP주소는 클라이언트와 서버 고정적 결합
- 정적 IP 주소 의존은 동적 클라우드 네이티스 서비스에 적합하지 않음
- 경로를 동적으로 찾을 수 있는 간접화 필요
- Service Discovery는 클라이언트가 주소를 명시적으로 알고 있어야한다는 제한점 해결
- 서비스들의 주소를 자동으로 탐지하고 관리
- 서버측도 서비스 주소 자동으로 탐지하여 물리적인 제약없이 서비스를 운영
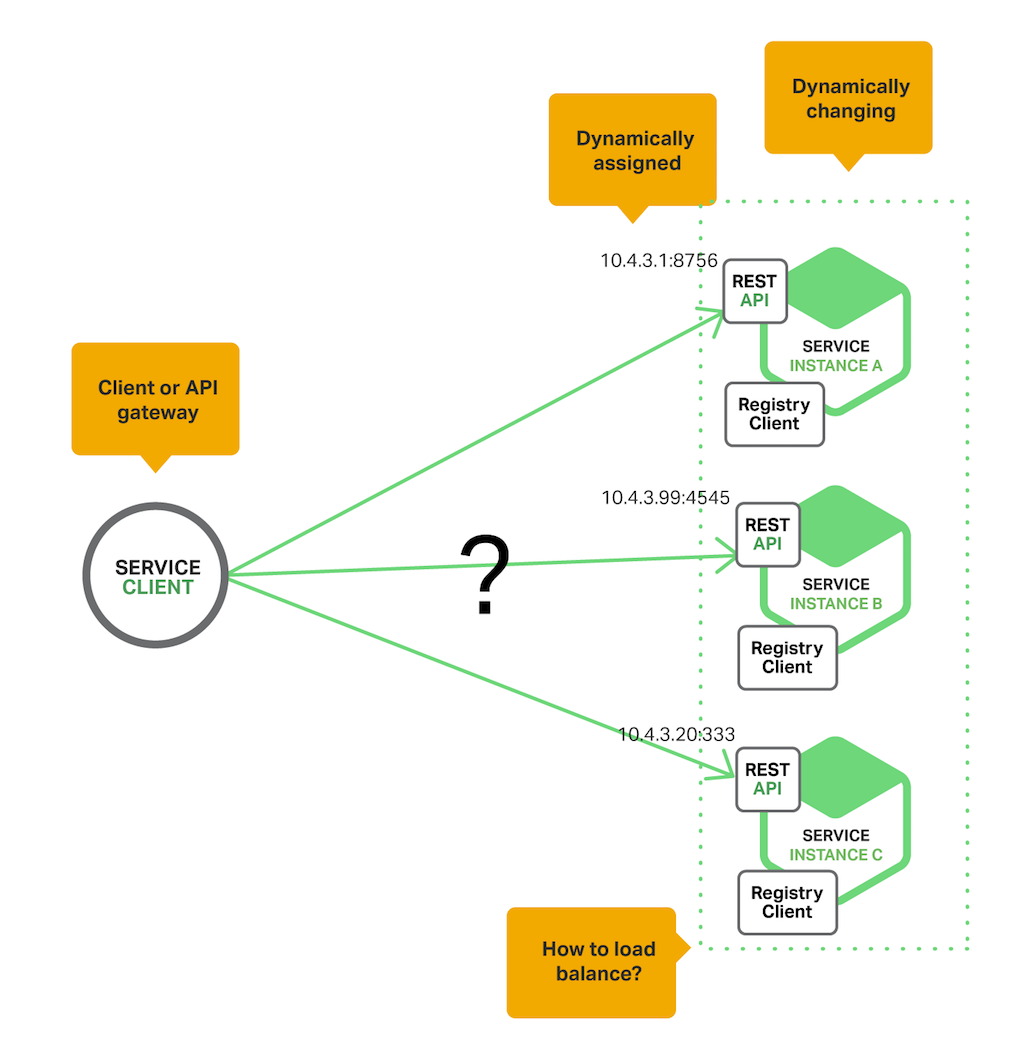
- Client‑Side Discovery Pattern
- 클라이언트가 특정 서비스 레지스트리를 통해 사용 가능한 서비스 인스턴스의 네트워크 위치를 판별
- 서비스 레지스트리가 모든 서비스 인스턴스 주소 정보를 알고 있기에 로드밸런스 가능
- 불필요한 네트워크 부하 감소
- 서비스 인스턴스가 시작될 때 서비스 인스턴스의 네트워크 위치가 서비스 레지스트리에 등록
- 인스턴스가 종료되면 서비스 레지스트리에서 제거
- 서비스 인스턴스의 등록은 일반적으로 하트 비트 메커니즘을 사용하여 주기적으로 새로 고쳐짐
- 하트 비트 매커니즘 : 관리자와 에이전트 간의 연결을 모니터하고 연결이 끊어지면 정리 절차를 자동화
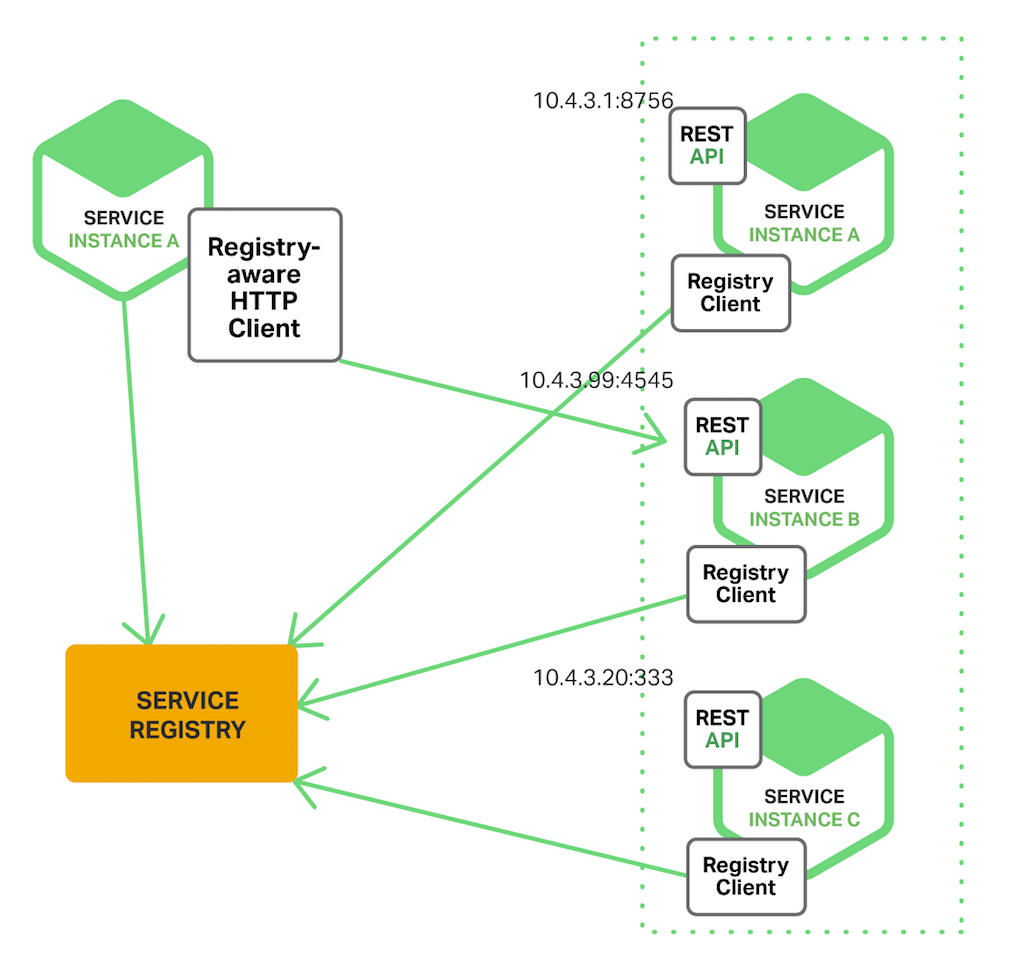
- 클라이언트 측 검색 패턴의 좋은 예
- Netflix OSS
- 서비스 레지스트리
- Netflix Eureka
- 서비스 인스턴스 등록을 관리하고 사용 가능한 인스턴스를 쿼리하기위한 REST API를 제공
- 장점
- 비교적 간단
- 서비스 레지스트리 제외 다른 동작 부분 없음
- 단점
- 클라이언트를 서비스 레지스트리와 결합
- 클라이언트가 Service Discovery를 위한 추가적인 기능을 개발 필요
- Server?Side Discovery Pattern
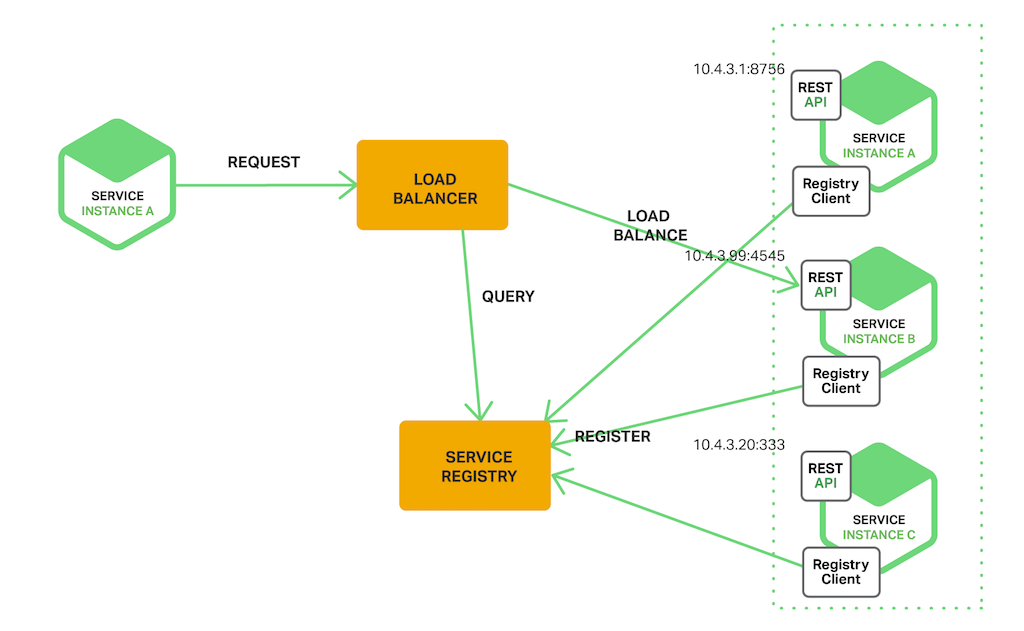
- 클라이언트 로드 밸런서 통해 서비스 요청
- Server‑Side Discovery Pattern 예
- AWS Elastic Load Balancer
- ELB 일반적으로 인터넷에서 외부 트래픽을 로드 밸런싱
- 클라이언트는 DNS 이름을 사용하여 ELB를 통해 요청
- ELB 로드 밸런서가 트래픽의 균형을 조정
- 장점
- 클라이언트 추상화
- 클라이언트는 단순히로드 밸런서에 요청
- 서비스 클라이언트가 사용하는 각 프로그래밍 언어 및 프레임 워크에 대한 다른 작업 필요가 없음
- 일부 환경에서 상위 추상화 기능 무료로 제공
- 단점
- 로드밸런서 부분 single point of failure(SPOF) 될 수 있기 때문에 높은 고가용성이 요구
- Service Registry
- Service Discovery의 핵심 부분
- 쉽게 서비스 인스턴스 네트워크 위치를 포함하는 데이터베이스
- 항상 가용성이 높고 최신 상태 유지
- 클라이언트는 서비스 레지스트리에서 얻은 네트워크 위치 캐시 가능
- 하지만 캐시한 정보는 결국 변경되고 클라이언트는 서비스 인스턴스 찾을 수 없음
- Netflix Eureka 훌륭한 모범 답안
- 서비스 인스턴스 등록, 조회 위한 REST API 제공
- POST Request 사용하여 네트워크 위치 등록
- 30 초마다 PUT Request 사용하여 등록 새로고침
- HTTP DELETE Request 사용 또는 인스턴스 등록 시간 초과에 의해 제거
참고 : https://www.nginx.com/blog/service-discovery-in-a-microservices-architecture/